class: center, middle, inverse, title-slide # Utilizando o Pycaret com dados do Covid-19 ### Francisco Rosa Dias de Miranda ### Predict - ICMC ### Novembro 2021 --- class: center <div> <style type="text/css">.xaringan-extra-logo { width: 110px; height: 128px; z-index: 0; background-image: url(https://github.com/predict-icmc/presentations/raw/master/logo-predict.png); background-size: contain; background-repeat: no-repeat; position: absolute; top:1em;right:1em; } </style> <script>(function () { let tries = 0 function addLogo () { if (typeof slideshow === 'undefined') { tries += 1 if (tries < 10) { setTimeout(addLogo, 100) } } else { document.querySelectorAll('.remark-slide-content:not(.title-slide):not(.inverse):not(.hide_logo)') .forEach(function (slide) { const logo = document.createElement('div') logo.classList = 'xaringan-extra-logo' logo.href = null slide.appendChild(logo) }) } } document.addEventListener('DOMContentLoaded', addLogo) })()</script> </div> ## Sobre a apresentação - **Motivação**: o pipeline padrão de um cientista de dados requer muitas linhas de código. - **Objetivo**: apresentar o módulo `pycaret` como maneira de resolver problemas do Predict em 2020 e 2021, indicar como utilizá-lo como ferramenta. --- ## Qual o foco de nossa análise? - **2020**: Modelos de regressão - **Resposta**: total acumulado de casos - **Modelo**: Gompertz - **Resposta**: novos casos /óbitos diários - **Modelo**: SARIMA, Redes Neurais - **2021**: Modelos de classificação - **Resposta**: indivíduo veio óbito ou não - **Modelo**: Regressão logística, ... --- class: center, middle <div id="htmlwidget-855dbdfde354e30cf3d0" style="width:100%;height:85%;" class="plotly html-widget"></div> <script type="application/json" data-for="htmlwidget-855dbdfde354e30cf3d0">{"x":{"data":[{"x":[31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120],"y":[1053,1223,1406,1451,1517,2339,2981,3506,4048,4466,4620,4866,5682,6708,7480,8216,8419,8755,8895,9371,11043,11568,12841,13894,14267,14580,15385,15914,16740,17826,20004,20715,21696,24041,26158,28698,30374,31174,31772,32187,34053,37853,39928,41830,44411,45444,46131,47719,51097,54286,58378,61183,62345,63066,65995,69859,73739,76871,80558,82161,83625,86017,89483,95865,101556,107142,109698,111296,118295,123483,129200,134565,140549,143073,144593,150138,156316,162520,167900,172875,178202,181460,190285,191517,192628,211658,215793,219185,221973,229475],"text":["tempo: 31<br />totalCases: 1053","tempo: 32<br />totalCases: 1223","tempo: 33<br />totalCases: 1406","tempo: 34<br />totalCases: 1451","tempo: 35<br />totalCases: 1517","tempo: 36<br />totalCases: 2339","tempo: 37<br />totalCases: 2981","tempo: 38<br />totalCases: 3506","tempo: 39<br />totalCases: 4048","tempo: 40<br />totalCases: 4466","tempo: 41<br />totalCases: 4620","tempo: 42<br />totalCases: 4866","tempo: 43<br />totalCases: 5682","tempo: 44<br />totalCases: 6708","tempo: 45<br />totalCases: 7480","tempo: 46<br />totalCases: 8216","tempo: 47<br />totalCases: 8419","tempo: 48<br />totalCases: 8755","tempo: 49<br />totalCases: 8895","tempo: 50<br />totalCases: 9371","tempo: 51<br />totalCases: 11043","tempo: 52<br />totalCases: 11568","tempo: 53<br />totalCases: 12841","tempo: 54<br />totalCases: 13894","tempo: 55<br />totalCases: 14267","tempo: 56<br />totalCases: 14580","tempo: 57<br />totalCases: 15385","tempo: 58<br />totalCases: 15914","tempo: 59<br />totalCases: 16740","tempo: 60<br />totalCases: 17826","tempo: 61<br />totalCases: 20004","tempo: 62<br />totalCases: 20715","tempo: 63<br />totalCases: 21696","tempo: 64<br />totalCases: 24041","tempo: 65<br />totalCases: 26158","tempo: 66<br />totalCases: 28698","tempo: 67<br />totalCases: 30374","tempo: 68<br />totalCases: 31174","tempo: 69<br />totalCases: 31772","tempo: 70<br />totalCases: 32187","tempo: 71<br />totalCases: 34053","tempo: 72<br />totalCases: 37853","tempo: 73<br />totalCases: 39928","tempo: 74<br />totalCases: 41830","tempo: 75<br />totalCases: 44411","tempo: 76<br />totalCases: 45444","tempo: 77<br />totalCases: 46131","tempo: 78<br />totalCases: 47719","tempo: 79<br />totalCases: 51097","tempo: 80<br />totalCases: 54286","tempo: 81<br />totalCases: 58378","tempo: 82<br />totalCases: 61183","tempo: 83<br />totalCases: 62345","tempo: 84<br />totalCases: 63066","tempo: 85<br />totalCases: 65995","tempo: 86<br />totalCases: 69859","tempo: 87<br />totalCases: 73739","tempo: 88<br />totalCases: 76871","tempo: 89<br />totalCases: 80558","tempo: 90<br />totalCases: 82161","tempo: 91<br />totalCases: 83625","tempo: 92<br />totalCases: 86017","tempo: 93<br />totalCases: 89483","tempo: 94<br />totalCases: 95865","tempo: 95<br />totalCases: 101556","tempo: 96<br />totalCases: 107142","tempo: 97<br />totalCases: 109698","tempo: 98<br />totalCases: 111296","tempo: 99<br />totalCases: 118295","tempo: 100<br />totalCases: 123483","tempo: 101<br />totalCases: 129200","tempo: 102<br />totalCases: 134565","tempo: 103<br />totalCases: 140549","tempo: 104<br />totalCases: 143073","tempo: 105<br />totalCases: 144593","tempo: 106<br />totalCases: 150138","tempo: 107<br />totalCases: 156316","tempo: 108<br />totalCases: 162520","tempo: 109<br />totalCases: 167900","tempo: 110<br />totalCases: 172875","tempo: 111<br />totalCases: 178202","tempo: 112<br />totalCases: 181460","tempo: 113<br />totalCases: 190285","tempo: 114<br />totalCases: 191517","tempo: 115<br />totalCases: 192628","tempo: 116<br />totalCases: 211658","tempo: 117<br />totalCases: 215793","tempo: 118<br />totalCases: 219185","tempo: 119<br />totalCases: 221973","tempo: 120<br />totalCases: 229475"],"type":"scatter","mode":"lines","line":{"width":3.77952755905512,"color":"rgba(0,0,255,1)","dash":"solid"},"hoveron":"points","showlegend":false,"xaxis":"x","yaxis":"y","hoverinfo":"text","frame":null},{"x":[121,122,123,124,125,126,127,128,129,130],"y":[237378.25435294,243915.47942692,250544.781650554,257265.114153347,264075.382459525,270974.445809448,277961.118516602,285034.171357249,292192.332989791,299434.291400937],"text":["x: 121<br />y: 237378.3<br />colour: Gompertz","x: 122<br />y: 243915.5<br />colour: Gompertz","x: 123<br />y: 250544.8<br />colour: Gompertz","x: 124<br />y: 257265.1<br />colour: Gompertz","x: 125<br />y: 264075.4<br />colour: Gompertz","x: 126<br />y: 270974.4<br />colour: Gompertz","x: 127<br />y: 277961.1<br />colour: Gompertz","x: 128<br />y: 285034.2<br />colour: Gompertz","x: 129<br />y: 292192.3<br />colour: Gompertz","x: 130<br />y: 299434.3<br />colour: Gompertz"],"type":"scatter","mode":"markers","marker":{"autocolorscale":false,"color":"rgba(248,118,109,1)","opacity":1,"size":5.66929133858268,"symbol":"circle","line":{"width":1.88976377952756,"color":"rgba(248,118,109,1)"}},"hoveron":"points","name":"Gompertz","legendgroup":"Gompertz","showlegend":true,"xaxis":"x","yaxis":"y","hoverinfo":"text","frame":null},{"x":[121,122,123,124,125,126,127,128,129,130],"y":[242981.399110273,249672.930729731,256458.712914432,263337.674083246,270308.69392608,277370.604756472,284522.192900623,291762.200119845,299089.325063422,306502.224748927],"text":["x: 121<br />min: 201964.8<br />max: 283998.0","x: 122<br />min: 207526.7<br />max: 291819.1","x: 123<br />min: 213167.0<br />max: 299750.4","x: 124<br />min: 218884.8<br />max: 307790.6","x: 125<br />min: 224679.1<br />max: 315938.3","x: 126<br />min: 230548.9<br />max: 324192.3","x: 127<br />min: 236493.2<br />max: 332551.1","x: 128<br />min: 242511.1<br />max: 341013.3","x: 129<br />min: 248601.4<br />max: 349577.3","x: 130<br />min: 254762.9<br />max: 358241.5"],"type":"scatter","mode":"lines","opacity":0.6,"line":{"color":"transparent"},"error_y":{"array":[41016.6272220393,42146.1954070313,43291.6736177049,44452.8809651369,45629.6283346802,46821.7186142905,48028.9469290022,49251.1008810457,50487.9607950988,51739.2999681717],"arrayminus":[41016.6272220393,42146.1954070312,43291.673617705,44452.8809651369,45629.6283346801,46821.7186142905,48028.9469290022,49251.1008810458,50487.9607950989,51739.2999681717],"type":"data","width":1.38214726450021,"symmetric":false,"color":"rgba(0,0,0,1)"},"showlegend":false,"xaxis":"x","yaxis":"y","hoverinfo":"text","frame":null}],"layout":{"margin":{"t":40.8401826484018,"r":7.30593607305936,"b":37.2602739726027,"l":54.7945205479452},"plot_bgcolor":"rgba(255,255,255,1)","paper_bgcolor":"rgba(255,255,255,1)","font":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187},"title":{"text":"Previsão de casos confirmados de COVID-19","font":{"color":"rgba(0,0,0,1)","family":"","size":17.5342465753425},"x":0,"xref":"paper"},"xaxis":{"domain":[0,1],"automargin":true,"type":"linear","autorange":false,"range":[26.0275,135.4225],"tickmode":"array","ticktext":["50","75","100","125"],"tickvals":[50,75,100,125],"categoryorder":"array","categoryarray":["50","75","100","125"],"nticks":null,"ticks":"outside","tickcolor":"rgba(51,51,51,1)","ticklen":3.65296803652968,"tickwidth":0.66417600664176,"showticklabels":true,"tickfont":{"color":"rgba(77,77,77,1)","family":"","size":11.689497716895},"tickangle":-0,"showline":false,"linecolor":null,"linewidth":0,"showgrid":true,"gridcolor":"rgba(235,235,235,1)","gridwidth":0.66417600664176,"zeroline":false,"anchor":"y","title":{"text":"Dias","font":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187}},"hoverformat":".2f"},"yaxis":{"domain":[0,1],"automargin":true,"type":"linear","autorange":false,"range":[-16806.426235855,376100.950952954],"tickmode":"array","ticktext":["0e+00","1e+05","2e+05","3e+05"],"tickvals":[0,100000,200000,300000],"categoryorder":"array","categoryarray":["0e+00","1e+05","2e+05","3e+05"],"nticks":null,"ticks":"outside","tickcolor":"rgba(51,51,51,1)","ticklen":3.65296803652968,"tickwidth":0.66417600664176,"showticklabels":true,"tickfont":{"color":"rgba(77,77,77,1)","family":"","size":11.689497716895},"tickangle":-0,"showline":false,"linecolor":null,"linewidth":0,"showgrid":true,"gridcolor":"rgba(235,235,235,1)","gridwidth":0.66417600664176,"zeroline":false,"anchor":"x","title":{"text":"Total de casos confirmados","font":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187}},"hoverformat":".2f"},"shapes":[{"type":"rect","fillcolor":"transparent","line":{"color":"rgba(51,51,51,1)","width":0.66417600664176,"linetype":"solid"},"yref":"paper","xref":"paper","x0":0,"x1":1,"y0":0,"y1":1}],"showlegend":true,"legend":{"bgcolor":"rgba(255,255,255,1)","bordercolor":"transparent","borderwidth":1.88976377952756,"font":{"color":"rgba(0,0,0,1)","family":"","size":11.689497716895},"y":0.938132733408324},"annotations":[{"text":"Modelo","x":1.02,"y":1,"showarrow":false,"ax":0,"ay":0,"font":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187},"xref":"paper","yref":"paper","textangle":-0,"xanchor":"left","yanchor":"bottom","legendTitle":true}],"hovermode":"closest","barmode":"relative"},"config":{"doubleClick":"reset","showSendToCloud":false},"source":"A","attrs":{"203275679e42":{"x":{},"y":{},"type":"scatter"},"20323db546a1":{"x":{},"y":{},"colour":{}},"20322d47bf0d":{"x":{},"ymin":{},"ymax":{}}},"cur_data":"203275679e42","visdat":{"203275679e42":["function (y) ","x"],"20323db546a1":["function (y) ","x"],"20322d47bf0d":["function (y) ","x"]},"highlight":{"on":"plotly_click","persistent":false,"dynamic":false,"selectize":false,"opacityDim":0.2,"selected":{"opacity":1},"debounce":0},"shinyEvents":["plotly_hover","plotly_click","plotly_selected","plotly_relayout","plotly_brushed","plotly_brushing","plotly_clickannotation","plotly_doubleclick","plotly_deselect","plotly_afterplot","plotly_sunburstclick"],"base_url":"https://plot.ly"},"evals":[],"jsHooks":[]}</script> --- class: center, middle <div id="htmlwidget-bed42d7af01a70e30740" style="width:100%;height:85%;" class="plotly html-widget"></div> <script type="application/json" data-for="htmlwidget-bed42d7af01a70e30740">{"x":{"visdat":{"153c470623fe":["function () ","plotlyVisDat"]},"cur_data":"153c470623fe","attrs":{"153c470623fe":{"alpha_stroke":1,"sizes":[10,100],"spans":[1,20],"line":{"color":"rgba(0,0,0,1)","fillcolor":"rgba(0,0,0,1)"},"mode":"lines","name":"observed","type":"scatter","x":["2020-02-25","2020-02-26","2020-02-27","2020-02-28","2020-02-29","2020-03-01","2020-03-02","2020-03-03","2020-03-04","2020-03-05","2020-03-06","2020-03-07","2020-03-08","2020-03-09","2020-03-10","2020-03-11","2020-03-12","2020-03-13","2020-03-14","2020-03-15","2020-03-16","2020-03-17","2020-03-18","2020-03-19","2020-03-20","2020-03-21","2020-03-22","2020-03-23","2020-03-24","2020-03-25","2020-03-26","2020-03-27","2020-03-28","2020-03-29","2020-03-30","2020-03-31","2020-04-01","2020-04-02","2020-04-03","2020-04-04","2020-04-05","2020-04-06","2020-04-07","2020-04-08","2020-04-09","2020-04-10","2020-04-11","2020-04-12","2020-04-13","2020-04-14","2020-04-15","2020-04-16","2020-04-17","2020-04-18","2020-04-19","2020-04-20","2020-04-21","2020-04-22","2020-04-23","2020-04-24","2020-04-25","2020-04-26","2020-04-27","2020-04-28","2020-04-29","2020-04-30","2020-05-01","2020-05-02","2020-05-03","2020-05-04","2020-05-05","2020-05-06","2020-05-07","2020-05-08","2020-05-09","2020-05-10","2020-05-11","2020-05-12","2020-05-13","2020-05-14","2020-05-15","2020-05-16","2020-05-17","2020-05-18","2020-05-19","2020-05-20","2020-05-21","2020-05-22","2020-05-23","2020-05-24","2020-05-25","2020-05-26","2020-05-27","2020-05-28","2020-05-29","2020-05-30","2020-05-31","2020-06-01","2020-06-02","2020-06-03","2020-06-04","2020-06-05","2020-06-06","2020-06-07","2020-06-08","2020-06-09","2020-06-10","2020-06-11","2020-06-12","2020-06-13","2020-06-14","2020-06-15","2020-06-16","2020-06-17","2020-06-18","2020-06-19","2020-06-20","2020-06-21","2020-06-22","2020-06-23","2020-06-24","2020-06-25","2020-06-26","2020-06-27","2020-06-28","2020-06-29","2020-06-30","2020-07-01","2020-07-02","2020-07-03","2020-07-04","2020-07-05","2020-07-06","2020-07-07","2020-07-08","2020-07-09","2020-07-10","2020-07-11","2020-07-12","2020-07-13","2020-07-14","2020-07-15","2020-07-16","2020-07-17","2020-07-18","2020-07-19","2020-07-20","2020-07-21","2020-07-22","2020-07-23","2020-07-24","2020-07-25","2020-07-26","2020-07-27","2020-07-28","2020-07-29","2020-07-30","2020-07-31","2020-08-01","2020-08-02","2020-08-03","2020-08-04","2020-08-05","2020-08-06","2020-08-07","2020-08-08","2020-08-09","2020-08-10","2020-08-11","2020-08-12","2020-08-13","2020-08-14","2020-08-15","2020-08-16","2020-08-17","2020-08-18","2020-08-19","2020-08-20","2020-08-21","2020-08-22","2020-08-23","2020-08-24","2020-08-25","2020-08-26","2020-08-27","2020-08-28","2020-08-29","2020-08-30","2020-08-31","2020-09-01","2020-09-02","2020-09-03","2020-09-04","2020-09-05","2020-09-06","2020-09-07","2020-09-08","2020-09-09","2020-09-10","2020-09-11","2020-09-12","2020-09-13","2020-09-14","2020-09-15","2020-09-16","2020-09-17","2020-09-18","2020-09-19","2020-09-20","2020-09-21","2020-09-22","2020-09-23","2020-09-24","2020-09-25","2020-09-26","2020-09-27","2020-09-28","2020-09-29","2020-09-30","2020-10-01","2020-10-02","2020-10-03","2020-10-04","2020-10-05","2020-10-06","2020-10-07","2020-10-08","2020-10-09","2020-10-10","2020-10-11","2020-10-12","2020-10-13","2020-10-14","2020-10-15","2020-10-16","2020-10-17","2020-10-18","2020-10-19","2020-10-20","2020-10-21","2020-10-22","2020-10-23","2020-10-24","2020-10-25","2020-10-26","2020-10-27","2020-10-28","2020-10-29","2020-10-30","2020-10-31","2020-11-01","2020-11-02","2020-11-03","2020-11-04","2020-11-05","2020-11-06","2020-11-07","2020-11-08","2020-11-09","2020-11-10","2020-11-11","2020-11-12","2020-11-13","2020-11-14","2020-11-15","2020-11-16","2020-11-17","2020-11-18","2020-11-19","2020-11-20","2020-11-21","2020-11-22","2020-11-23","2020-11-24","2020-11-25","2020-11-26","2020-11-27","2020-11-28","2020-11-29","2020-11-30","2020-12-01","2020-12-02","2020-12-03","2020-12-04","2020-12-05","2020-12-06","2020-12-07","2020-12-08","2020-12-09","2020-12-10","2020-12-11","2020-12-12","2020-12-13","2020-12-14","2020-12-15","2020-12-16","2020-12-17","2020-12-18","2020-12-19","2020-12-20","2020-12-21","2020-12-22","2020-12-23","2020-12-24","2020-12-25","2020-12-26","2020-12-27","2020-12-28","2020-12-29","2020-12-30","2020-12-31","2021-01-01","2021-01-02","2021-01-03","2021-01-04","2021-01-05","2021-01-06","2021-01-07","2021-01-08","2021-01-09","2021-01-10","2021-01-11","2021-01-12","2021-01-13","2021-01-14","2021-01-15","2021-01-16","2021-01-17","2021-01-18","2021-01-19","2021-01-20","2021-01-21","2021-01-22","2021-01-23","2021-01-24","2021-01-25","2021-01-26","2021-01-27","2021-01-28","2021-01-29","2021-01-30","2021-01-31","2021-02-01","2021-02-02","2021-02-03","2021-02-04","2021-02-05","2021-02-06","2021-02-07","2021-02-08","2021-02-09","2021-02-10","2021-02-11","2021-02-12","2021-02-13","2021-02-14","2021-02-15","2021-02-16","2021-02-17","2021-02-18","2021-02-19","2021-02-20","2021-02-21","2021-02-22","2021-02-23","2021-02-24","2021-02-25","2021-02-26","2021-02-27","2021-02-28"],"y":[null,null,null,null,null,null,0,0,0,1,1,2,2,2,2,4,6,7,7,17,19,21,30,34,49,56,71,85,92,89,110,118,135,117,110,218,303,350,404,437,453,478,478,532,568,595,565,591,576,527,619,584,661,782,787,812,859,696,739,712,873,921,1017,1237,1463,1708,1793,1596,1580,1499,1430,1671,1604,1637,1891,1953,1992,1952,1892,2051,2364,2396,2414,2419,2611,2680,2779,2642,2768,2831,2937,2860,2803,3161,3526,3798,3934,3953,4611,4857,4762,4716,4772,4768,4757,4549,4690,4760,4762,4618,5018,5267,5735,5029,4301,6251,6131,5855,5788,5599,6758,7994,6693,7113,7507,7596,7415,7302,7656,7456,6707,6920,6846,7333,7347,6791,6915,7766,7403,7362,7700,7402,7476,6901,6448,6150,5975,5152,6610,7137,7972,9636,9848,10174,11090,10679,11000,11298,10405,10672,10366,10755,10153,9952,9439,9916,9777,9742,9139,9988,10826,11106,10828,10338,10607,10281,9457,8053,7120,7388,7805,7688,7734,7823,7661,8607,7454,7039,6837,6958,7171,7646,6972,7380,7474,7570,6344,5749,5254,5399,5372,5219,5146,6070,6122,6010,5960,5855,6149,6283,6307,6078,5917,5770,5602,5277,5116,4871,4808,4784,4630,4649,4524,4491,4474,4447,4383,4408,4484,4823,4824,4027,4044,4173,4150,3974,3706,3671,4276,4029,3618,3772,3803,4054,4115,4178,4332,4560,4307,3839,3595,3565,2905,2817,2439,1735,1401,1256,1163,4130,3939,4388,5264,5927,6101,6206,4375,4803,4948,5367,5430,5850,5893,5396,5750,5425,4748,4666,4412,4433,4964,4994,5521,6080,6713,6756,6746,6602,6697,6923,7002,6954,6706,6877,6375,4978,6480,6642,7191,7057,7290,8190,9673,8109,7205,5606,6011,5673,5925,6134,6258,6301,6373,6464,6560,6617,7001,7552,8966,10366,10673,10782,10756,10862,10810,10985,11301,11315,11304,11769,11645,11418,10559,10677,10584,10575,10147,10380,10759,11457,11238,11134,11061,11252,10816,10696,10458,10295,10281,10293,10137,10256,9861,9773,9475,9181,9163,8919,8559,8499,8427,8573,8904,8938,9021,9133,9296,9366,9406,9386],"xaxis":"x","yaxis":"y","inherit":true},"153c470623fe.1":{"alpha_stroke":1,"sizes":[10,100],"spans":[1,20],"fill":"toself","line":{"color":"rgba(242,242,242,1)","fillcolor":"rgba(242,242,242,1)"},"mode":"lines","name":"95% confidence","type":"scatter","x":["2021-03-01","2021-03-02","2021-03-03","2021-03-04","2021-03-05","2021-03-06","2021-03-07","2021-03-08","2021-03-09","2021-03-10","2021-03-11","2021-03-12","2021-03-13","2021-03-14","2021-03-14","2021-03-13","2021-03-12","2021-03-11","2021-03-10","2021-03-09","2021-03-08","2021-03-07","2021-03-06","2021-03-05","2021-03-04","2021-03-03","2021-03-02","2021-03-01"],"y":[10181,10695,11069,11386,11782,11916,12056,12052,11958,11912,11985,11926,11896,11794,6275,6365,6481,6475,6486,6645,6735,6737,6842,7111,7395,7842,8289,8753],"xaxis":"x","yaxis":"y","hoveron":"points","inherit":true},"153c470623fe.2":{"alpha_stroke":1,"sizes":[10,100],"spans":[1,20],"fill":"toself","line":{"color":"rgba(204,204,204,1)","fillcolor":"rgba(204,204,204,1)"},"mode":"lines","name":"80% confidence","type":"scatter","x":["2021-03-01","2021-03-02","2021-03-03","2021-03-04","2021-03-05","2021-03-06","2021-03-07","2021-03-08","2021-03-09","2021-03-10","2021-03-11","2021-03-12","2021-03-13","2021-03-14","2021-03-14","2021-03-13","2021-03-12","2021-03-11","2021-03-10","2021-03-09","2021-03-08","2021-03-07","2021-03-06","2021-03-05","2021-03-04","2021-03-03","2021-03-02","2021-03-01"],"y":[9893,10292,10614,10833,11021,11291,11466,11431,11362,11388,11297,11278,11216,11227,7127,7164,7100,7271,7208,7243,7306,7414,7633,7829,8027,8415,8702,9007],"xaxis":"x","yaxis":"y","hoveron":"points","inherit":true},"153c470623fe.3":{"alpha_stroke":1,"sizes":[10,100],"spans":[1,20],"line":{"color":"rgba(0,0,255,1)","fillcolor":"rgba(0,0,255,1)"},"mode":"lines","name":"prediction","type":"scatter","x":["2021-03-01","2021-03-02","2021-03-03","2021-03-04","2021-03-05","2021-03-06","2021-03-07","2021-03-08","2021-03-09","2021-03-10","2021-03-11","2021-03-12","2021-03-13","2021-03-14"],"y":[9475,9565,9658,9716,9814,9933,10087,10213,10336,10449,10571,10669,10742,10782],"xaxis":"x","yaxis":"y","inherit":true},"153c470623fe.4":{"alpha_stroke":1,"sizes":[10,100],"spans":[1,20],"x":["2020-02-25","2020-02-26","2020-02-27","2020-02-28","2020-02-29","2020-03-01","2020-03-02","2020-03-03","2020-03-04","2020-03-05","2020-03-06","2020-03-07","2020-03-08","2020-03-09","2020-03-10","2020-03-11","2020-03-12","2020-03-13","2020-03-14","2020-03-15","2020-03-16","2020-03-17","2020-03-18","2020-03-19","2020-03-20","2020-03-21","2020-03-22","2020-03-23","2020-03-24","2020-03-25","2020-03-26","2020-03-27","2020-03-28","2020-03-29","2020-03-30","2020-03-31","2020-04-01","2020-04-02","2020-04-03","2020-04-04","2020-04-05","2020-04-06","2020-04-07","2020-04-08","2020-04-09","2020-04-10","2020-04-11","2020-04-12","2020-04-13","2020-04-14","2020-04-15","2020-04-16","2020-04-17","2020-04-18","2020-04-19","2020-04-20","2020-04-21","2020-04-22","2020-04-23","2020-04-24","2020-04-25","2020-04-26","2020-04-27","2020-04-28","2020-04-29","2020-04-30","2020-05-01","2020-05-02","2020-05-03","2020-05-04","2020-05-05","2020-05-06","2020-05-07","2020-05-08","2020-05-09","2020-05-10","2020-05-11","2020-05-12","2020-05-13","2020-05-14","2020-05-15","2020-05-16","2020-05-17","2020-05-18","2020-05-19","2020-05-20","2020-05-21","2020-05-22","2020-05-23","2020-05-24","2020-05-25","2020-05-26","2020-05-27","2020-05-28","2020-05-29","2020-05-30","2020-05-31","2020-06-01","2020-06-02","2020-06-03","2020-06-04","2020-06-05","2020-06-06","2020-06-07","2020-06-08","2020-06-09","2020-06-10","2020-06-11","2020-06-12","2020-06-13","2020-06-14","2020-06-15","2020-06-16","2020-06-17","2020-06-18","2020-06-19","2020-06-20","2020-06-21","2020-06-22","2020-06-23","2020-06-24","2020-06-25","2020-06-26","2020-06-27","2020-06-28","2020-06-29","2020-06-30","2020-07-01","2020-07-02","2020-07-03","2020-07-04","2020-07-05","2020-07-06","2020-07-07","2020-07-08","2020-07-09","2020-07-10","2020-07-11","2020-07-12","2020-07-13","2020-07-14","2020-07-15","2020-07-16","2020-07-17","2020-07-18","2020-07-19","2020-07-20","2020-07-21","2020-07-22","2020-07-23","2020-07-24","2020-07-25","2020-07-26","2020-07-27","2020-07-28","2020-07-29","2020-07-30","2020-07-31","2020-08-01","2020-08-02","2020-08-03","2020-08-04","2020-08-05","2020-08-06","2020-08-07","2020-08-08","2020-08-09","2020-08-10","2020-08-11","2020-08-12","2020-08-13","2020-08-14","2020-08-15","2020-08-16","2020-08-17","2020-08-18","2020-08-19","2020-08-20","2020-08-21","2020-08-22","2020-08-23","2020-08-24","2020-08-25","2020-08-26","2020-08-27","2020-08-28","2020-08-29","2020-08-30","2020-08-31","2020-09-01","2020-09-02","2020-09-03","2020-09-04","2020-09-05","2020-09-06","2020-09-07","2020-09-08","2020-09-09","2020-09-10","2020-09-11","2020-09-12","2020-09-13","2020-09-14","2020-09-15","2020-09-16","2020-09-17","2020-09-18","2020-09-19","2020-09-20","2020-09-21","2020-09-22","2020-09-23","2020-09-24","2020-09-25","2020-09-26","2020-09-27","2020-09-28","2020-09-29","2020-09-30","2020-10-01","2020-10-02","2020-10-03","2020-10-04","2020-10-05","2020-10-06","2020-10-07","2020-10-08","2020-10-09","2020-10-10","2020-10-11","2020-10-12","2020-10-13","2020-10-14","2020-10-15","2020-10-16","2020-10-17","2020-10-18","2020-10-19","2020-10-20","2020-10-21","2020-10-22","2020-10-23","2020-10-24","2020-10-25","2020-10-26","2020-10-27","2020-10-28","2020-10-29","2020-10-30","2020-10-31","2020-11-01","2020-11-02","2020-11-03","2020-11-04","2020-11-05","2020-11-06","2020-11-07","2020-11-08","2020-11-09","2020-11-10","2020-11-11","2020-11-12","2020-11-13","2020-11-14","2020-11-15","2020-11-16","2020-11-17","2020-11-18","2020-11-19","2020-11-20","2020-11-21","2020-11-22","2020-11-23","2020-11-24","2020-11-25","2020-11-26","2020-11-27","2020-11-28","2020-11-29","2020-11-30","2020-12-01","2020-12-02","2020-12-03","2020-12-04","2020-12-05","2020-12-06","2020-12-07","2020-12-08","2020-12-09","2020-12-10","2020-12-11","2020-12-12","2020-12-13","2020-12-14","2020-12-15","2020-12-16","2020-12-17","2020-12-18","2020-12-19","2020-12-20","2020-12-21","2020-12-22","2020-12-23","2020-12-24","2020-12-25","2020-12-26","2020-12-27","2020-12-28","2020-12-29","2020-12-30","2020-12-31","2021-01-01","2021-01-02","2021-01-03","2021-01-04","2021-01-05","2021-01-06","2021-01-07","2021-01-08","2021-01-09","2021-01-10","2021-01-11","2021-01-12","2021-01-13","2021-01-14","2021-01-15","2021-01-16","2021-01-17","2021-01-18","2021-01-19","2021-01-20","2021-01-21","2021-01-22","2021-01-23","2021-01-24","2021-01-25","2021-01-26","2021-01-27","2021-01-28","2021-01-29","2021-01-30","2021-01-31","2021-02-01","2021-02-02","2021-02-03","2021-02-04","2021-02-05","2021-02-06","2021-02-07","2021-02-08","2021-02-09","2021-02-10","2021-02-11","2021-02-12","2021-02-13","2021-02-14","2021-02-15","2021-02-16","2021-02-17","2021-02-18","2021-02-19","2021-02-20","2021-02-21","2021-02-22","2021-02-23","2021-02-24","2021-02-25","2021-02-26","2021-02-27","2021-02-28"],"y":[1,0,0,1,0,0,0,0,1,3,4,3,3,0,3,11,16,10,9,71,16,12,77,45,110,63,172,114,65,52,191,170,183,45,66,822,642,525,542,418,154,246,816,1026,772,736,203,336,140,476,1672,525,1273,1053,373,313,805,529,826,1086,2178,711,981,2345,2117,2540,1676,800,598,415,1866,3800,2075,1902,2581,1033,687,1588,3378,3189,4092,2805,1162,721,2929,3864,3880,3132,3687,1603,1464,2392,3466,6382,5691,5586,2556,1598,6999,5188,5717,5365,5984,2524,1520,5545,6178,6204,5380,4975,5327,3258,8825,1232,1111,19030,4135,3392,2788,7502,9347,9765,9921,7073,6156,3408,6235,8555,12244,8523,1828,7649,2891,9638,8657,8350,9395,7780,5107,2610,12000,6569,8872,5367,4612,3022,1385,6235,16777,12561,11211,16263,4501,3672,12647,13896,14809,13298,10014,6367,1533,15371,9676,13405,9709,13352,5395,1289,11147,15619,19274,11667,11408,1963,3172,8865,9847,9451,5132,13284,4885,2351,9190,10465,8318,11756,5213,1982,938,10033,11956,11647,7038,8069,2637,1608,1453,7793,8178,8055,7881,1567,1092,7922,8157,7393,7711,7141,3627,2032,8090,6551,6267,6681,5967,1349,905,6377,6109,6097,5608,6096,473,677,6260,5916,5649,5786,6626,2844,684,685,6031,6553,5627,5394,968,437,4923,4299,3678,6702,5614,2725,863,5364,5375,5278,4928,2339,1020,648,749,4755,2637,0,0,0,0,21515,3421,5780,6130,4640,1218,737,8698,6421,6794,9058,5087,4153,1037,5219,8900,4523,4320,4507,2379,1180,8937,9114,8208,8237,8938,2675,1116,7923,9784,9786,8791,8601,940,2313,4412,0,20303,9922,12447,0,3943,10714,10383,9351,3596,1253,2836,1576,12477,11849,10219,3894,1762,3469,2248,12881,14534,14073,13794,11561,5619,3010,12702,15275,13710,15016,13774,5720,2933,15953,14411,12118,9005,14596,5072,2867,12959,16041,14776,13887,13067,4344,2354,14297,12990,13932,12222,11923,4248,2442,13201,13825,11167,11605,9837,2187,2316,11496,11302,10747,11105,10859,4504,2550,12077,12086,11889,11596,11142,4361],"type":"bar","name":"Novos casos diários","inherit":true}},"layout":{"margin":{"b":40,"l":60,"t":25,"r":10},"title":"Forecast from NNAR","xaxis":{"domain":["2020-02-25","2021-02-28"],"automargin":true,"title":" "},"yaxis":{"domain":[0,1],"automargin":true,"title":"Novos Casos Confirmados (Média Móvel de 7 dias)"},"legend":{"orientation":"h"},"hovermode":"closest","showlegend":true},"source":"A","config":{"showSendToCloud":false},"data":[{"line":{"color":"rgba(0,0,0,1)","fillcolor":"rgba(0,0,0,1)"},"mode":"lines","name":"observed","type":"scatter","x":["2020-03-02","2020-03-03","2020-03-04","2020-03-05","2020-03-06","2020-03-07","2020-03-08","2020-03-09","2020-03-10","2020-03-11","2020-03-12","2020-03-13","2020-03-14","2020-03-15","2020-03-16","2020-03-17","2020-03-18","2020-03-19","2020-03-20","2020-03-21","2020-03-22","2020-03-23","2020-03-24","2020-03-25","2020-03-26","2020-03-27","2020-03-28","2020-03-29","2020-03-30","2020-03-31","2020-04-01","2020-04-02","2020-04-03","2020-04-04","2020-04-05","2020-04-06","2020-04-07","2020-04-08","2020-04-09","2020-04-10","2020-04-11","2020-04-12","2020-04-13","2020-04-14","2020-04-15","2020-04-16","2020-04-17","2020-04-18","2020-04-19","2020-04-20","2020-04-21","2020-04-22","2020-04-23","2020-04-24","2020-04-25","2020-04-26","2020-04-27","2020-04-28","2020-04-29","2020-04-30","2020-05-01","2020-05-02","2020-05-03","2020-05-04","2020-05-05","2020-05-06","2020-05-07","2020-05-08","2020-05-09","2020-05-10","2020-05-11","2020-05-12","2020-05-13","2020-05-14","2020-05-15","2020-05-16","2020-05-17","2020-05-18","2020-05-19","2020-05-20","2020-05-21","2020-05-22","2020-05-23","2020-05-24","2020-05-25","2020-05-26","2020-05-27","2020-05-28","2020-05-29","2020-05-30","2020-05-31","2020-06-01","2020-06-02","2020-06-03","2020-06-04","2020-06-05","2020-06-06","2020-06-07","2020-06-08","2020-06-09","2020-06-10","2020-06-11","2020-06-12","2020-06-13","2020-06-14","2020-06-15","2020-06-16","2020-06-17","2020-06-18","2020-06-19","2020-06-20","2020-06-21","2020-06-22","2020-06-23","2020-06-24","2020-06-25","2020-06-26","2020-06-27","2020-06-28","2020-06-29","2020-06-30","2020-07-01","2020-07-02","2020-07-03","2020-07-04","2020-07-05","2020-07-06","2020-07-07","2020-07-08","2020-07-09","2020-07-10","2020-07-11","2020-07-12","2020-07-13","2020-07-14","2020-07-15","2020-07-16","2020-07-17","2020-07-18","2020-07-19","2020-07-20","2020-07-21","2020-07-22","2020-07-23","2020-07-24","2020-07-25","2020-07-26","2020-07-27","2020-07-28","2020-07-29","2020-07-30","2020-07-31","2020-08-01","2020-08-02","2020-08-03","2020-08-04","2020-08-05","2020-08-06","2020-08-07","2020-08-08","2020-08-09","2020-08-10","2020-08-11","2020-08-12","2020-08-13","2020-08-14","2020-08-15","2020-08-16","2020-08-17","2020-08-18","2020-08-19","2020-08-20","2020-08-21","2020-08-22","2020-08-23","2020-08-24","2020-08-25","2020-08-26","2020-08-27","2020-08-28","2020-08-29","2020-08-30","2020-08-31","2020-09-01","2020-09-02","2020-09-03","2020-09-04","2020-09-05","2020-09-06","2020-09-07","2020-09-08","2020-09-09","2020-09-10","2020-09-11","2020-09-12","2020-09-13","2020-09-14","2020-09-15","2020-09-16","2020-09-17","2020-09-18","2020-09-19","2020-09-20","2020-09-21","2020-09-22","2020-09-23","2020-09-24","2020-09-25","2020-09-26","2020-09-27","2020-09-28","2020-09-29","2020-09-30","2020-10-01","2020-10-02","2020-10-03","2020-10-04","2020-10-05","2020-10-06","2020-10-07","2020-10-08","2020-10-09","2020-10-10","2020-10-11","2020-10-12","2020-10-13","2020-10-14","2020-10-15","2020-10-16","2020-10-17","2020-10-18","2020-10-19","2020-10-20","2020-10-21","2020-10-22","2020-10-23","2020-10-24","2020-10-25","2020-10-26","2020-10-27","2020-10-28","2020-10-29","2020-10-30","2020-10-31","2020-11-01","2020-11-02","2020-11-03","2020-11-04","2020-11-05","2020-11-06","2020-11-07","2020-11-08","2020-11-09","2020-11-10","2020-11-11","2020-11-12","2020-11-13","2020-11-14","2020-11-15","2020-11-16","2020-11-17","2020-11-18","2020-11-19","2020-11-20","2020-11-21","2020-11-22","2020-11-23","2020-11-24","2020-11-25","2020-11-26","2020-11-27","2020-11-28","2020-11-29","2020-11-30","2020-12-01","2020-12-02","2020-12-03","2020-12-04","2020-12-05","2020-12-06","2020-12-07","2020-12-08","2020-12-09","2020-12-10","2020-12-11","2020-12-12","2020-12-13","2020-12-14","2020-12-15","2020-12-16","2020-12-17","2020-12-18","2020-12-19","2020-12-20","2020-12-21","2020-12-22","2020-12-23","2020-12-24","2020-12-25","2020-12-26","2020-12-27","2020-12-28","2020-12-29","2020-12-30","2020-12-31","2021-01-01","2021-01-02","2021-01-03","2021-01-04","2021-01-05","2021-01-06","2021-01-07","2021-01-08","2021-01-09","2021-01-10","2021-01-11","2021-01-12","2021-01-13","2021-01-14","2021-01-15","2021-01-16","2021-01-17","2021-01-18","2021-01-19","2021-01-20","2021-01-21","2021-01-22","2021-01-23","2021-01-24","2021-01-25","2021-01-26","2021-01-27","2021-01-28","2021-01-29","2021-01-30","2021-01-31","2021-02-01","2021-02-02","2021-02-03","2021-02-04","2021-02-05","2021-02-06","2021-02-07","2021-02-08","2021-02-09","2021-02-10","2021-02-11","2021-02-12","2021-02-13","2021-02-14","2021-02-15","2021-02-16","2021-02-17","2021-02-18","2021-02-19","2021-02-20","2021-02-21","2021-02-22","2021-02-23","2021-02-24","2021-02-25","2021-02-26","2021-02-27","2021-02-28"],"y":[0,0,0,1,1,2,2,2,2,4,6,7,7,17,19,21,30,34,49,56,71,85,92,89,110,118,135,117,110,218,303,350,404,437,453,478,478,532,568,595,565,591,576,527,619,584,661,782,787,812,859,696,739,712,873,921,1017,1237,1463,1708,1793,1596,1580,1499,1430,1671,1604,1637,1891,1953,1992,1952,1892,2051,2364,2396,2414,2419,2611,2680,2779,2642,2768,2831,2937,2860,2803,3161,3526,3798,3934,3953,4611,4857,4762,4716,4772,4768,4757,4549,4690,4760,4762,4618,5018,5267,5735,5029,4301,6251,6131,5855,5788,5599,6758,7994,6693,7113,7507,7596,7415,7302,7656,7456,6707,6920,6846,7333,7347,6791,6915,7766,7403,7362,7700,7402,7476,6901,6448,6150,5975,5152,6610,7137,7972,9636,9848,10174,11090,10679,11000,11298,10405,10672,10366,10755,10153,9952,9439,9916,9777,9742,9139,9988,10826,11106,10828,10338,10607,10281,9457,8053,7120,7388,7805,7688,7734,7823,7661,8607,7454,7039,6837,6958,7171,7646,6972,7380,7474,7570,6344,5749,5254,5399,5372,5219,5146,6070,6122,6010,5960,5855,6149,6283,6307,6078,5917,5770,5602,5277,5116,4871,4808,4784,4630,4649,4524,4491,4474,4447,4383,4408,4484,4823,4824,4027,4044,4173,4150,3974,3706,3671,4276,4029,3618,3772,3803,4054,4115,4178,4332,4560,4307,3839,3595,3565,2905,2817,2439,1735,1401,1256,1163,4130,3939,4388,5264,5927,6101,6206,4375,4803,4948,5367,5430,5850,5893,5396,5750,5425,4748,4666,4412,4433,4964,4994,5521,6080,6713,6756,6746,6602,6697,6923,7002,6954,6706,6877,6375,4978,6480,6642,7191,7057,7290,8190,9673,8109,7205,5606,6011,5673,5925,6134,6258,6301,6373,6464,6560,6617,7001,7552,8966,10366,10673,10782,10756,10862,10810,10985,11301,11315,11304,11769,11645,11418,10559,10677,10584,10575,10147,10380,10759,11457,11238,11134,11061,11252,10816,10696,10458,10295,10281,10293,10137,10256,9861,9773,9475,9181,9163,8919,8559,8499,8427,8573,8904,8938,9021,9133,9296,9366,9406,9386],"xaxis":"x","yaxis":"y","marker":{"color":"rgba(31,119,180,1)","line":{"color":"rgba(31,119,180,1)"}},"error_y":{"color":"rgba(31,119,180,1)"},"error_x":{"color":"rgba(31,119,180,1)"},"frame":null},{"fillcolor":"rgba(255,127,14,0.5)","fill":"toself","line":{"color":"rgba(242,242,242,1)","fillcolor":"rgba(242,242,242,1)"},"mode":"lines","name":"95% confidence","type":"scatter","x":["2021-03-01","2021-03-02","2021-03-03","2021-03-04","2021-03-05","2021-03-06","2021-03-07","2021-03-08","2021-03-09","2021-03-10","2021-03-11","2021-03-12","2021-03-13","2021-03-14","2021-03-14","2021-03-13","2021-03-12","2021-03-11","2021-03-10","2021-03-09","2021-03-08","2021-03-07","2021-03-06","2021-03-05","2021-03-04","2021-03-03","2021-03-02","2021-03-01"],"y":[10181,10695,11069,11386,11782,11916,12056,12052,11958,11912,11985,11926,11896,11794,6275,6365,6481,6475,6486,6645,6735,6737,6842,7111,7395,7842,8289,8753],"xaxis":"x","yaxis":"y","hoveron":"points","marker":{"color":"rgba(255,127,14,1)","line":{"color":"rgba(255,127,14,1)"}},"error_y":{"color":"rgba(255,127,14,1)"},"error_x":{"color":"rgba(255,127,14,1)"},"frame":null},{"fillcolor":"rgba(44,160,44,0.5)","fill":"toself","line":{"color":"rgba(204,204,204,1)","fillcolor":"rgba(204,204,204,1)"},"mode":"lines","name":"80% confidence","type":"scatter","x":["2021-03-01","2021-03-02","2021-03-03","2021-03-04","2021-03-05","2021-03-06","2021-03-07","2021-03-08","2021-03-09","2021-03-10","2021-03-11","2021-03-12","2021-03-13","2021-03-14","2021-03-14","2021-03-13","2021-03-12","2021-03-11","2021-03-10","2021-03-09","2021-03-08","2021-03-07","2021-03-06","2021-03-05","2021-03-04","2021-03-03","2021-03-02","2021-03-01"],"y":[9893,10292,10614,10833,11021,11291,11466,11431,11362,11388,11297,11278,11216,11227,7127,7164,7100,7271,7208,7243,7306,7414,7633,7829,8027,8415,8702,9007],"xaxis":"x","yaxis":"y","hoveron":"points","marker":{"color":"rgba(44,160,44,1)","line":{"color":"rgba(44,160,44,1)"}},"error_y":{"color":"rgba(44,160,44,1)"},"error_x":{"color":"rgba(44,160,44,1)"},"frame":null},{"line":{"color":"rgba(0,0,255,1)","fillcolor":"rgba(0,0,255,1)"},"mode":"lines","name":"prediction","type":"scatter","x":["2021-03-01","2021-03-02","2021-03-03","2021-03-04","2021-03-05","2021-03-06","2021-03-07","2021-03-08","2021-03-09","2021-03-10","2021-03-11","2021-03-12","2021-03-13","2021-03-14"],"y":[9475,9565,9658,9716,9814,9933,10087,10213,10336,10449,10571,10669,10742,10782],"xaxis":"x","yaxis":"y","marker":{"color":"rgba(214,39,40,1)","line":{"color":"rgba(214,39,40,1)"}},"error_y":{"color":"rgba(214,39,40,1)"},"error_x":{"color":"rgba(214,39,40,1)"},"frame":null},{"x":["2020-02-25","2020-02-26","2020-02-27","2020-02-28","2020-02-29","2020-03-01","2020-03-02","2020-03-03","2020-03-04","2020-03-05","2020-03-06","2020-03-07","2020-03-08","2020-03-09","2020-03-10","2020-03-11","2020-03-12","2020-03-13","2020-03-14","2020-03-15","2020-03-16","2020-03-17","2020-03-18","2020-03-19","2020-03-20","2020-03-21","2020-03-22","2020-03-23","2020-03-24","2020-03-25","2020-03-26","2020-03-27","2020-03-28","2020-03-29","2020-03-30","2020-03-31","2020-04-01","2020-04-02","2020-04-03","2020-04-04","2020-04-05","2020-04-06","2020-04-07","2020-04-08","2020-04-09","2020-04-10","2020-04-11","2020-04-12","2020-04-13","2020-04-14","2020-04-15","2020-04-16","2020-04-17","2020-04-18","2020-04-19","2020-04-20","2020-04-21","2020-04-22","2020-04-23","2020-04-24","2020-04-25","2020-04-26","2020-04-27","2020-04-28","2020-04-29","2020-04-30","2020-05-01","2020-05-02","2020-05-03","2020-05-04","2020-05-05","2020-05-06","2020-05-07","2020-05-08","2020-05-09","2020-05-10","2020-05-11","2020-05-12","2020-05-13","2020-05-14","2020-05-15","2020-05-16","2020-05-17","2020-05-18","2020-05-19","2020-05-20","2020-05-21","2020-05-22","2020-05-23","2020-05-24","2020-05-25","2020-05-26","2020-05-27","2020-05-28","2020-05-29","2020-05-30","2020-05-31","2020-06-01","2020-06-02","2020-06-03","2020-06-04","2020-06-05","2020-06-06","2020-06-07","2020-06-08","2020-06-09","2020-06-10","2020-06-11","2020-06-12","2020-06-13","2020-06-14","2020-06-15","2020-06-16","2020-06-17","2020-06-18","2020-06-19","2020-06-20","2020-06-21","2020-06-22","2020-06-23","2020-06-24","2020-06-25","2020-06-26","2020-06-27","2020-06-28","2020-06-29","2020-06-30","2020-07-01","2020-07-02","2020-07-03","2020-07-04","2020-07-05","2020-07-06","2020-07-07","2020-07-08","2020-07-09","2020-07-10","2020-07-11","2020-07-12","2020-07-13","2020-07-14","2020-07-15","2020-07-16","2020-07-17","2020-07-18","2020-07-19","2020-07-20","2020-07-21","2020-07-22","2020-07-23","2020-07-24","2020-07-25","2020-07-26","2020-07-27","2020-07-28","2020-07-29","2020-07-30","2020-07-31","2020-08-01","2020-08-02","2020-08-03","2020-08-04","2020-08-05","2020-08-06","2020-08-07","2020-08-08","2020-08-09","2020-08-10","2020-08-11","2020-08-12","2020-08-13","2020-08-14","2020-08-15","2020-08-16","2020-08-17","2020-08-18","2020-08-19","2020-08-20","2020-08-21","2020-08-22","2020-08-23","2020-08-24","2020-08-25","2020-08-26","2020-08-27","2020-08-28","2020-08-29","2020-08-30","2020-08-31","2020-09-01","2020-09-02","2020-09-03","2020-09-04","2020-09-05","2020-09-06","2020-09-07","2020-09-08","2020-09-09","2020-09-10","2020-09-11","2020-09-12","2020-09-13","2020-09-14","2020-09-15","2020-09-16","2020-09-17","2020-09-18","2020-09-19","2020-09-20","2020-09-21","2020-09-22","2020-09-23","2020-09-24","2020-09-25","2020-09-26","2020-09-27","2020-09-28","2020-09-29","2020-09-30","2020-10-01","2020-10-02","2020-10-03","2020-10-04","2020-10-05","2020-10-06","2020-10-07","2020-10-08","2020-10-09","2020-10-10","2020-10-11","2020-10-12","2020-10-13","2020-10-14","2020-10-15","2020-10-16","2020-10-17","2020-10-18","2020-10-19","2020-10-20","2020-10-21","2020-10-22","2020-10-23","2020-10-24","2020-10-25","2020-10-26","2020-10-27","2020-10-28","2020-10-29","2020-10-30","2020-10-31","2020-11-01","2020-11-02","2020-11-03","2020-11-04","2020-11-05","2020-11-06","2020-11-07","2020-11-08","2020-11-09","2020-11-10","2020-11-11","2020-11-12","2020-11-13","2020-11-14","2020-11-15","2020-11-16","2020-11-17","2020-11-18","2020-11-19","2020-11-20","2020-11-21","2020-11-22","2020-11-23","2020-11-24","2020-11-25","2020-11-26","2020-11-27","2020-11-28","2020-11-29","2020-11-30","2020-12-01","2020-12-02","2020-12-03","2020-12-04","2020-12-05","2020-12-06","2020-12-07","2020-12-08","2020-12-09","2020-12-10","2020-12-11","2020-12-12","2020-12-13","2020-12-14","2020-12-15","2020-12-16","2020-12-17","2020-12-18","2020-12-19","2020-12-20","2020-12-21","2020-12-22","2020-12-23","2020-12-24","2020-12-25","2020-12-26","2020-12-27","2020-12-28","2020-12-29","2020-12-30","2020-12-31","2021-01-01","2021-01-02","2021-01-03","2021-01-04","2021-01-05","2021-01-06","2021-01-07","2021-01-08","2021-01-09","2021-01-10","2021-01-11","2021-01-12","2021-01-13","2021-01-14","2021-01-15","2021-01-16","2021-01-17","2021-01-18","2021-01-19","2021-01-20","2021-01-21","2021-01-22","2021-01-23","2021-01-24","2021-01-25","2021-01-26","2021-01-27","2021-01-28","2021-01-29","2021-01-30","2021-01-31","2021-02-01","2021-02-02","2021-02-03","2021-02-04","2021-02-05","2021-02-06","2021-02-07","2021-02-08","2021-02-09","2021-02-10","2021-02-11","2021-02-12","2021-02-13","2021-02-14","2021-02-15","2021-02-16","2021-02-17","2021-02-18","2021-02-19","2021-02-20","2021-02-21","2021-02-22","2021-02-23","2021-02-24","2021-02-25","2021-02-26","2021-02-27","2021-02-28"],"y":[1,0,0,1,0,0,0,0,1,3,4,3,3,0,3,11,16,10,9,71,16,12,77,45,110,63,172,114,65,52,191,170,183,45,66,822,642,525,542,418,154,246,816,1026,772,736,203,336,140,476,1672,525,1273,1053,373,313,805,529,826,1086,2178,711,981,2345,2117,2540,1676,800,598,415,1866,3800,2075,1902,2581,1033,687,1588,3378,3189,4092,2805,1162,721,2929,3864,3880,3132,3687,1603,1464,2392,3466,6382,5691,5586,2556,1598,6999,5188,5717,5365,5984,2524,1520,5545,6178,6204,5380,4975,5327,3258,8825,1232,1111,19030,4135,3392,2788,7502,9347,9765,9921,7073,6156,3408,6235,8555,12244,8523,1828,7649,2891,9638,8657,8350,9395,7780,5107,2610,12000,6569,8872,5367,4612,3022,1385,6235,16777,12561,11211,16263,4501,3672,12647,13896,14809,13298,10014,6367,1533,15371,9676,13405,9709,13352,5395,1289,11147,15619,19274,11667,11408,1963,3172,8865,9847,9451,5132,13284,4885,2351,9190,10465,8318,11756,5213,1982,938,10033,11956,11647,7038,8069,2637,1608,1453,7793,8178,8055,7881,1567,1092,7922,8157,7393,7711,7141,3627,2032,8090,6551,6267,6681,5967,1349,905,6377,6109,6097,5608,6096,473,677,6260,5916,5649,5786,6626,2844,684,685,6031,6553,5627,5394,968,437,4923,4299,3678,6702,5614,2725,863,5364,5375,5278,4928,2339,1020,648,749,4755,2637,0,0,0,0,21515,3421,5780,6130,4640,1218,737,8698,6421,6794,9058,5087,4153,1037,5219,8900,4523,4320,4507,2379,1180,8937,9114,8208,8237,8938,2675,1116,7923,9784,9786,8791,8601,940,2313,4412,0,20303,9922,12447,0,3943,10714,10383,9351,3596,1253,2836,1576,12477,11849,10219,3894,1762,3469,2248,12881,14534,14073,13794,11561,5619,3010,12702,15275,13710,15016,13774,5720,2933,15953,14411,12118,9005,14596,5072,2867,12959,16041,14776,13887,13067,4344,2354,14297,12990,13932,12222,11923,4248,2442,13201,13825,11167,11605,9837,2187,2316,11496,11302,10747,11105,10859,4504,2550,12077,12086,11889,11596,11142,4361],"type":"bar","name":"Novos casos diários","marker":{"color":"rgba(148,103,189,1)","line":{"color":"rgba(148,103,189,1)"}},"error_y":{"color":"rgba(148,103,189,1)"},"error_x":{"color":"rgba(148,103,189,1)"},"xaxis":"x","yaxis":"y","frame":null}],"highlight":{"on":"plotly_click","persistent":false,"dynamic":false,"selectize":false,"opacityDim":0.2,"selected":{"opacity":1},"debounce":0},"shinyEvents":["plotly_hover","plotly_click","plotly_selected","plotly_relayout","plotly_brushed","plotly_brushing","plotly_clickannotation","plotly_doubleclick","plotly_deselect","plotly_afterplot","plotly_sunburstclick"],"base_url":"https://plot.ly"},"evals":[],"jsHooks":[]}</script> --- class: center, middle ## Pycaret <img src="https://miro.medium.com/max/625/1*2otHnNXOngAcvKzcTo_vlw.jpeg" width="70%" height="70%" /> Fonte: https://brianray-7981.medium.com/google-clouds-automl-first-look-cb7d29e06377 --- ## Pycaret **O que é?** - Uma biblioteca para automatizar o pipeline padrão de um experimento em ciência de dados. **Pró**: - Código mais compacto, robusto e interpretável; - É possível focar mais nos dados do que na programação. **Contra**: - Necessário conhecer muito bem a documentação para entender o que está sendo feito, senão tudo vira uma caixa preta. - Por estar em desenvolvimento, novos módulos podem surgir e outros ficarem _deprecated_ rapidamente. --- ## Instalação local - Altamente recomendável utilizar um ambiente virtual (a documentação explica como criar um) ```bash # install the full version of pycaret pip install pycaret[full] # time series module (beta) pip install pycaret-ts-alpha ``` Fonte: https://pycaret.readthedocs.io/en/latest/installation.html --- ## Collab Utilize a versão "slim" ```python !pip install pycaret ``` Também é necessário ativar o modo collab: ```python from pycaret.utils import enable_colab enable_colab() ``` Fonte: https://pycaret.readthedocs.io/en/latest/installation.html --- ## Carregando Módulos Atualmente, existem 6 módulos estáveis e um beta suportados. ```python from pycaret.classification import * # Classification from pycaret.regression import * # Regression from pycaret.clustering import * # Clustering from pycaret.anomaly import * # Anomaly Detection from pycaret.nlp import * # Natural Language Processing from pycaret.arules import * # Association Rule Mining from pycaret.time_series import * # Time Series (experimental) ``` -- - **Classificação**: prever a classe de novas observações; - **Regressão**: prever valores de novas observações; - **Detecção de Anomalias**: identificar valores ou eventos raros. - **Processamento de Linguagem Natural**: análise de corpus textuais; - **Association Rule Mining**: `\(\{cebolas, batatas\} \rightarrow \{tomate\}\)`; - **Séries Temporais** (beta) --- ## Setup Primeiro e único passo obrigarório em qualquer experimento. Embora o comando seja simples, muitas coisas acontecem aqui: - **Tipo dos dados**: inferido automaticamente, confira e pressione `enter`  Fonte: https://pycaret.org/setup/ --- ## Setup Também é possível passar os tipos diretamente através dos argumentos: ```python categorical = ['asma', 'diabetes', 'obesidade'] numeric = ['idade'] clf = setup(data = dados, target='obito', categorical_features = categorical, numeric_features = numeric, session_id = 4336) ``` - **session_id**: semente aleatória, para reprodutibilidade do experimento - **limpeza/preparação**: tratamento de dados faltantes, data inputting - **amostragem**: modelos preliminares com diferentes tamanhos amostrais - **data splitting**: a amostra é separada em treino e teste (70:30 por padrão) Fonte: https://pycaret.org/setup/ --- ## Comparando modelos Passo inicial no _workflow_ de qualquer experimento supervisionado. Todos os modelos da biblioteca são ajustados e suas métricas de performance são avaliadas. ```python compare_models() ``` 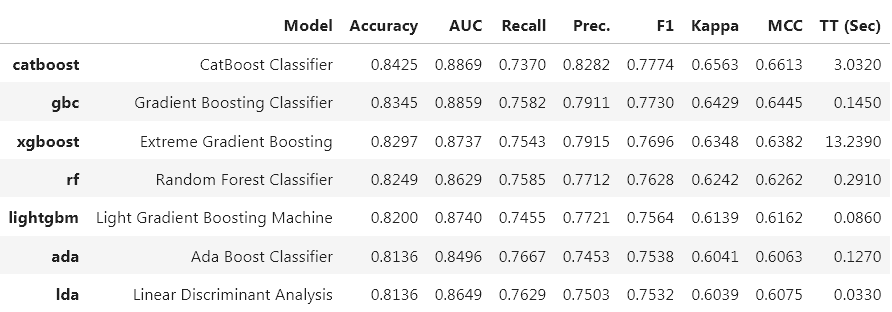 Fonte: https://pycaret.org/compare-models/ --- ## Ajustar o modelo Toma como parâmetro o ID do modelo e retorna uma tabela com métricas de validação cruzada em _k-folds_ (no caso supervisionado), assim como o modelo. Por padrão, o parâmetro `fold = 10`. ```python dt = create_model('dt') ``` Métricas de avaliação que podem ser utilizadas: - **Classificação**: Accuracy, AUC, Recall, Precision, F1, Kappa, MCC. - **Regressão**: MAE, MSE, RMSE, R2, RMSLE, MAPE Fonte: https://pycaret.org/create-model/ --- ## Tunar o modelo Encontra melhores hiperparâmetros do modelo criado através de um random grid search (modelos supervisionados). Similar à função `create_model()` ```python tuned_dt = tune_model(dt) ``` - Por padrão, essa função realiza 10 iterações aleatórias dentro do espaço de busca, controlado através do parâmetro `n_iter` - Aumentá-lo pode custar mais tempo, porém regularmente oferece um modelo melhor otimizado. - A métrica a ser otimizada pode ser definida através do parâmetro `optimize `. - Por padrão são utilizados o `\(R^2\)` em tarefas de Regressão, e a _acurácia_ na Classificação. Fonte: https://pycaret.org/tune-model/ --- ## Modelo ajustado  Fonte: https://cdn.motor1.com/images/mgl/PqO9K/s1/saveiro-surf-2015-cabine-simples-ja-e-vendida-por-r-48050.jpg --- ## Modelo tunado <img src="https://pbs.twimg.com/media/DwHbcrHXcAAZtp1.jpg" width="80%" height="85%" /> Fonte: https://pbs.twimg.com/media/DwHbcrHXcAAZtp1.jpg --- ## E em seguida? Depende da sua tarefa, do seu conhecimento e da sua disposição! Alguns passos extras para a modelagem: - Ensembling - Bagging - Boosting - Blending - Model voting - Stacking - Multiple Layer Fonte: https://www.pycaret.org/ensemble-model --- ## O que mais? - Análise do modelo - Plots - Interpretação - Deployment - Previsões ## Vamos programar! 1. `covid-class.ipynb` 1. `covid-ts.ipynb` --- ## O que vimos hoje? ### mini-pipeline do pycaret: 1. `setup()` 1. `create_model()` 1. `tune_model()` 1. `finalize_model()` --- class: center, middle, inverse ##"... all models are approximations. Essentially, all models are wrong, but some are useful. However, the approximate nature of the model must always be borne in mind...." # George Box